| Tweet |
Introduction
It's been a while since I made any changes to the Org Documentor, partly because I've been focused in other areas, and partly because I didn't need anything else documented. This changed with the Spring 22 release of Salesforce and the Flow Trigger Explorer.
I really liked the idea of the explorer, but was disappointed that it showed inactive flows and didn't reflect the new ordering capabilities. Why didn't they add that, I wondered. How hard could it be? Then it occurred to me that I could handle this myself through the Org Documentor. It turns out I couldn't handle all aspects, but still enough to be useful. More on that later.
Flow Support
Up until now I hadn't got around to including flows in the generated documentation, and this clearly needed to change if I wanted to output the order they were executed in.
As long as API version 54 is used, the execution order information comes back as expected, and getting these in the right order and handling collisions based on names is straightforward with a custom comparator function. Sadly I can't figure out the order when there is no execution information defined, as CreatedDate isn't available in the metadata. Two out of three ain't bad.
Order of Execution
As there are multiple steps in the order of execution, and most of those steps require different metadata, I couldn't handle it like I do other metadata. Simply processing the contents of a directory might help for one or two steps, but I wanted the consolidated view. To deal with this I create an order of execution data structure for each object that appears in the metadata, and gradually flesh this out as I process the various other types of metadata. So the objects add the validation rule information, triggers populate the before and after steps, as do flows.
As everyone knows, there's a lot of steps in the order of execution, and I'm not attempting to support all of them right now. Especially as some of them (write to database but don't commit) don't have anything that metadata influences! Rather than trying to detail this in a blog post that I'd have to update every time I change anything, the order of execution page contains all the steps and adds badges to show which are possible to support, and which are supported:
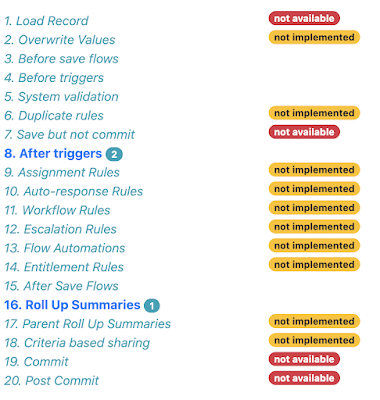
As you can see, at the time of writing it's triggers and flows plus validation rules and roll up summaries.
Steps where there is metadata that influences the behaviour appear in bold with a badge to indicate how many items there are. Clicking on the step takes you to the section that details the metadata:
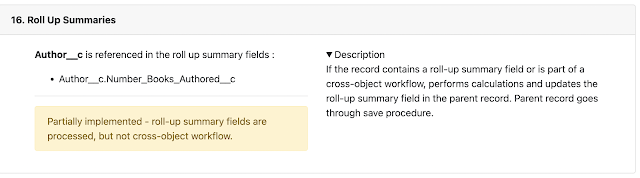
You can see an example of the order of execution generated from the sample metadata at the Heroku site.
Updated Plug-in
Related Posts
- The plug-in on NPMJS
- Documentation generated from the sample metadata
- Sample metadata repository
- Plug-in source repository
- Org Doumentor - Field Count Badges
- The Documentor Documented (and Moar Detail)
- Org Documentor - Flag Non-Display Fields
- Org Documentor - Custom Header Colours
- Org Documentor - A Little More Configuration
- Org Documentor - Fields Usage in Page Layout
- Org Documentor and AuraEnabled Classes
- Documentor Plugin - Triggers (and Bootstrap)
- Documenting from the metadata source with a Salesforce CLI Plug-in - Part 5
- Documenting from the metadata source with a Salesforce CLI Plug-in - Part 4
- Documenting from the metadata source with a Salesforce CLI Plug-In - Part 3
- Documenting from the metadata source with a Salesforce CLI Plug-In - Part 2
- Documenting from the metadata source with a Salesforce CLI Plug-In - Part 1
- Offline mobile app template plug-in Dreamforce 18 session
- Salesforce CLI Play-by-Play
- Salesforce CLI Cheat Sheet







