| Tweet |

Introduction
Earlier this year (2022) Salesforce Architects introduced a diagrammatic representation of the order of execution, which was a game changer in terms of easing understanding. I've had a task on my todo list since then to figure out how I could incorporate it into the Org Documentor, and thanks to using up some annual leave in a freezing December, I've finally had time to work on it.
Click to View
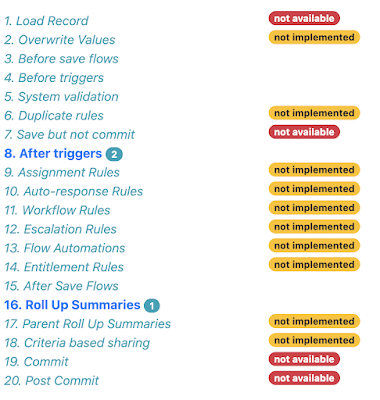
I already have information about the configured automation organised by the order of execution step, but currently in a text format:

so it made sense to try to repurpose this. I really liked the idea of making the diagram clickable, via an image map, but I wasn't overly keen on adding JavaScript to display popups with the details of the configured automation, so I went hunting for a CSS/HTML only solution.
I found it at
Mate Marschalko's Medium post, which showed how to use the :target pseudo-class to show or hide overlay
divs without a single line of JavaScript, so set about applying this technique
to the Org Documentor via a new EJS template, heavily based on my existing
order of execution template. I also needed to generate the image map element
based on selected areas of the Salesforce diagram, for which I used <img-map>
- I did find that it all went awry after I selected 4-5 areas, so I did them
one at a time and copied the coordinates over to my new template.
After a few hours work I had a reference to the Salesforce diagram in the
generated documentation for each object, via the new Image Detail column:

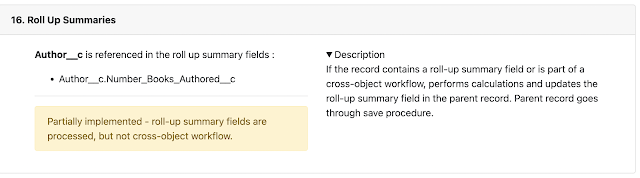
but with elements that could be clicked on:

which would display the automation configured for the object for that specific
step and a description if the user cared to read more.

Albeit with a couple of caveats:
-
Because the red line around the clickable element is applied to an
<area> element, these only display when the element is clicked. This
means that to find what is clickable you need to mouse around looking for
the change in the pointer (or look at the text version of the order of
execution for the object and identify what is supported there)
- The page jumps around a bit under you. This is due to the nature of the :target psueudo class - when you click on an element, the URL is updated with a fragment identifying the popup required, which transforms from zero size to it's configured size in the centre of the page. This causes the browser to scroll down to show it correctly. When you close the popup, the URL is changed to remove the fragment, which makes the browser jump to the top of the page. This could be obviated by using a smaller image, but my view is it's better to live with this and have an image that you can read.
Try it Yourself
Version 4.1. 0 of the plugin includes this functionality and is available
from NPM.
The sample output has been regenerated on Render,com, so if you access:
and click element 3 - Executes "Before Save" record triggered flows, you can
see it in action.
Related Posts
- The plug-in on NPMJS
- Documentation generated from the sample metadata
- Sample metadata repository
- Plug-in source repository
- Documentation for the Documentor
- The latest from the Org Documentor
- The Org Documentor keeps on Executing
- Org Documentor - (Some of) The Order of Execution
- Org Doumentor - Field Count Badges
- The Documentor Documented (and Moar Detail)
- Org Documentor - Flag Non-Display Fields
- Org Documentor - Custom Header Colours
- Org Documentor - A Little More Configuration
- Org Documentor - Fields Usage in Page Layout
- Org Documentor and AuraEnabled Classes
- Documentor Plugin - Triggers (and Bootstrap)
- Documenting from the metadata source with a Salesforce CLI Plug-in - Part 5
- Documenting from the metadata source with a Salesforce CLI Plug-in - Part 4
- Documenting from the metadata source with a Salesforce CLI Plug-In - Part 3
- Documenting from the metadata source with a Salesforce CLI Plug-In - Part 2
- Documenting from the metadata source with a Salesforce CLI Plug-In - Part 1
- Offline mobile app template plug-in Dreamforce 18 session
- Salesforce CLI Play-by-Play
- Salesforce CLI Cheat Sheet